Abstract
While current visual captioning models have achieved impressive performance, they often assume that the image is well-captured and provides a complete view of the scene. In real-world scenarios, however, a single image may not offer a good viewpoint, hindering fine-grained scene understanding. To overcome this limitation, we propose a novel task called Embodied Captioning, which equips visual captioning models with navigation capabilities, enabling them to actively explore the scene and reduce visual ambiguity from suboptimal viewpoints. Specifically, starting at a random viewpoint, an agent must navigate the environment to gather information from different viewpoints and generate a comprehensive paragraph describing all objects in the scene. To support this task, we build the ET-Cap dataset with Kubric simulator, consisting of 10K 3D scenes with cluttered objects and three annotated paragraphs per scene.
We propose a Cascade Embodied Captioning model (CaBOT), which comprises of a navigator and a captioner, to tackle this task. The navigator predicts which actions to take in the environment, while the captioner generates a paragraph description based on the whole navigation trajectory.
Extensive experiments demonstrate that our model outperforms other carefully designed baselines.
Introduction
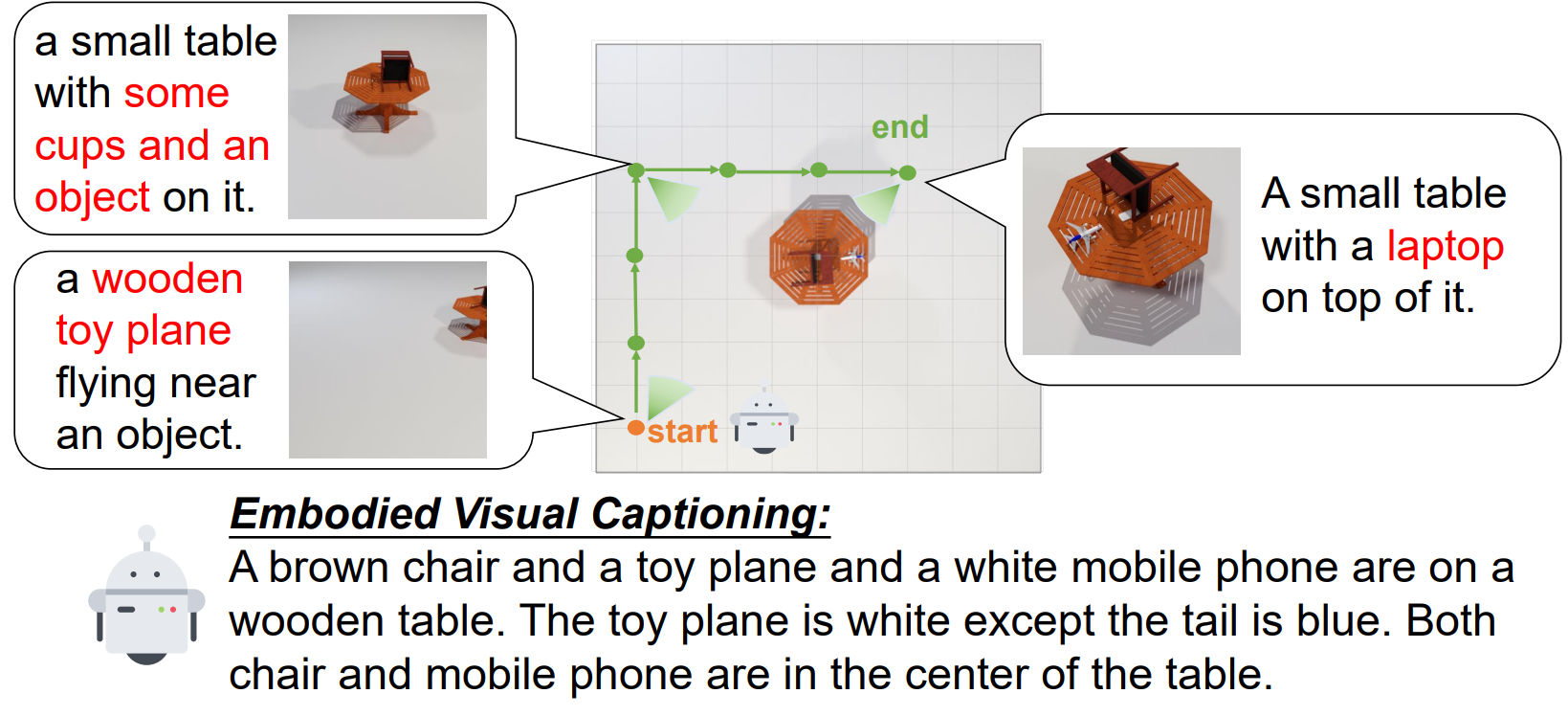
Figure 1: We propose a new Embodied Captioning task which allows agents to navigate the environment to reduce visual ambiguity of the scene.
Contributions
-
We propose a novel and challenging Embodied Captioning task which requires agents to explore in 3D environments to generate better visual descriptions.
-
A high-quality dataset is constructed to benchmark the Embodied Captioning task, with 10K synthetic 3D scenes and 24K manually annotated good viewpoints and 30K paragraph descriptions.
-
We present a Cascade Embodied Captioning model which incorporates navigation histories for captioning, providing a strong starting point for future work.
ET-Cap
CaBOT
Citation
@article{anwen2023explore,
title={Explore and Tell: Embodied Visual Captioning in 3D Environments},
author={Anwen, Hu and Shizhe, Chen and Liang, Zhang and Qin, Jin},
conference={ICCV},
}